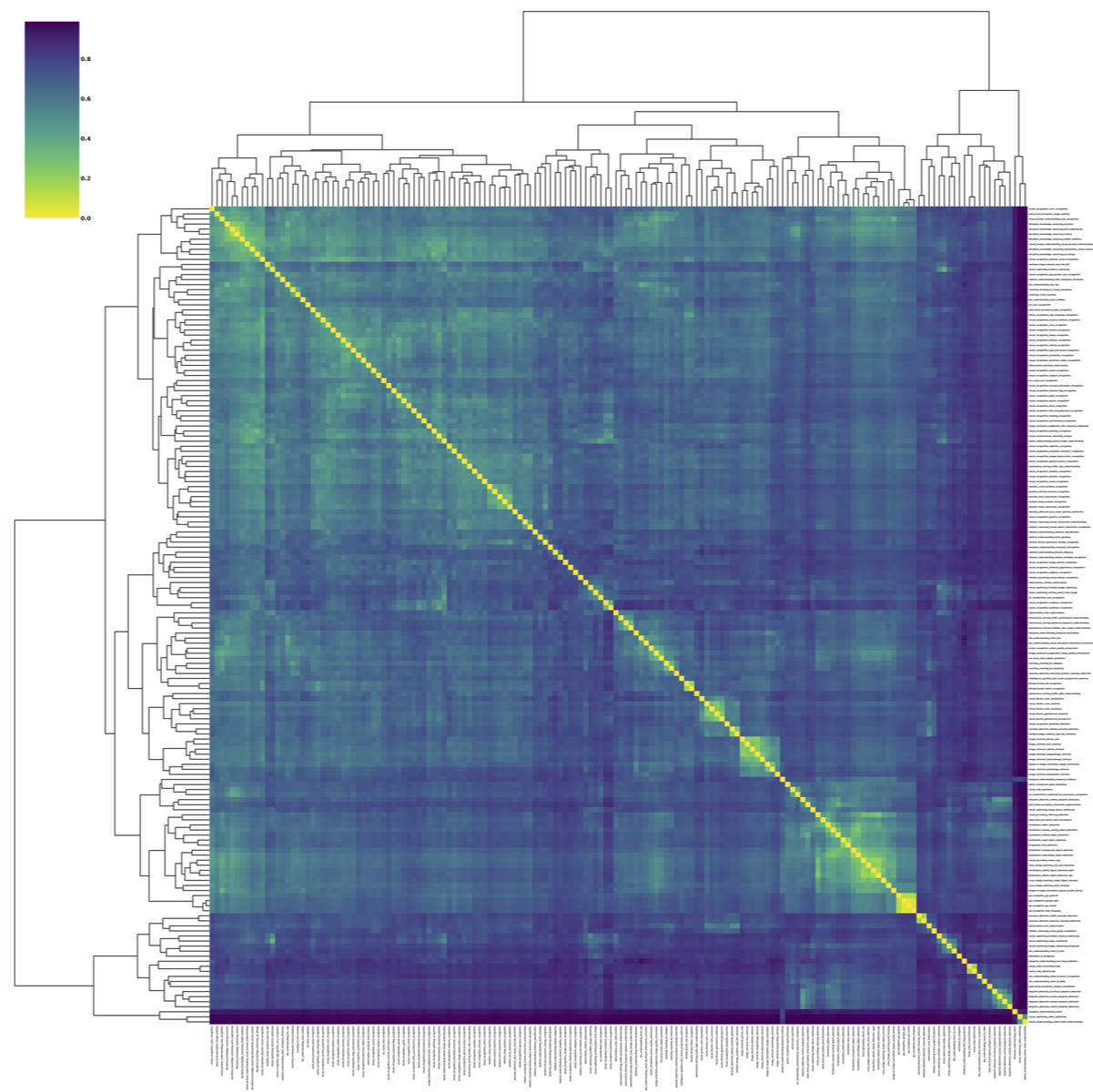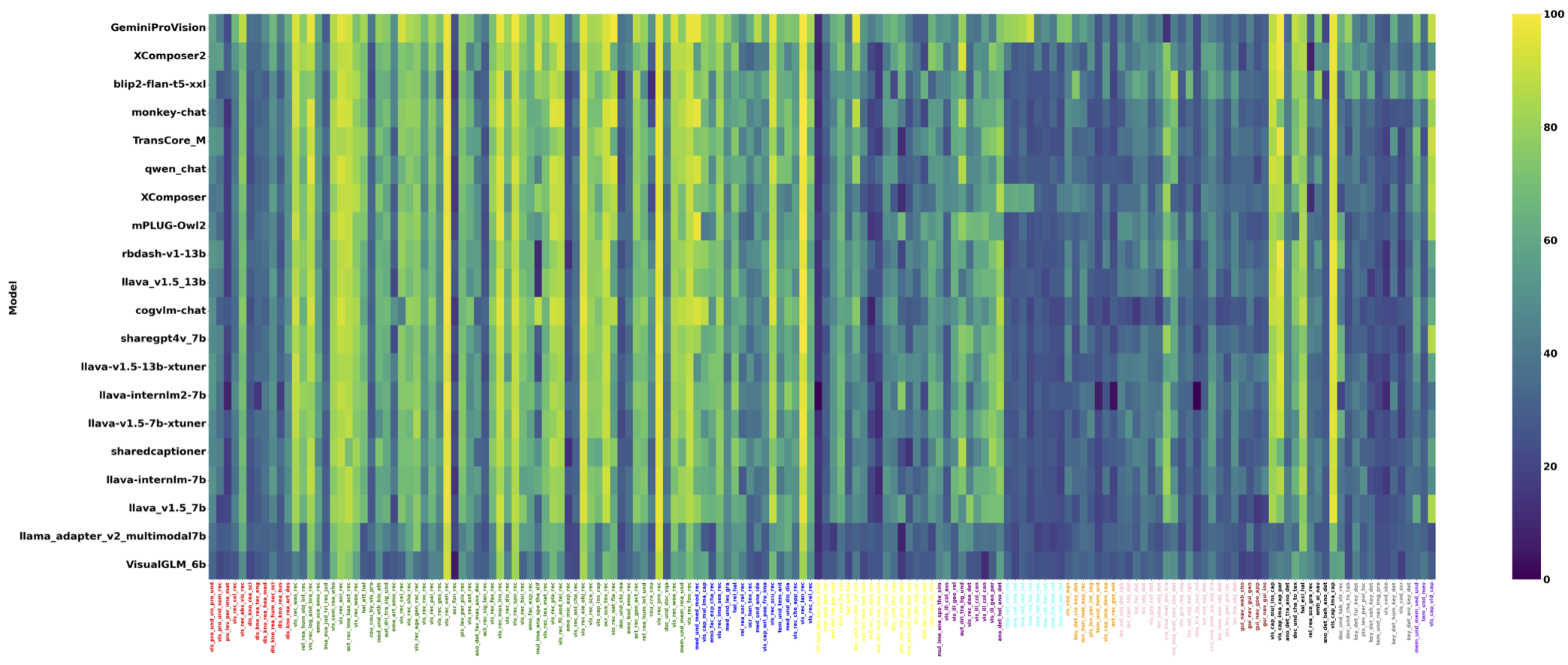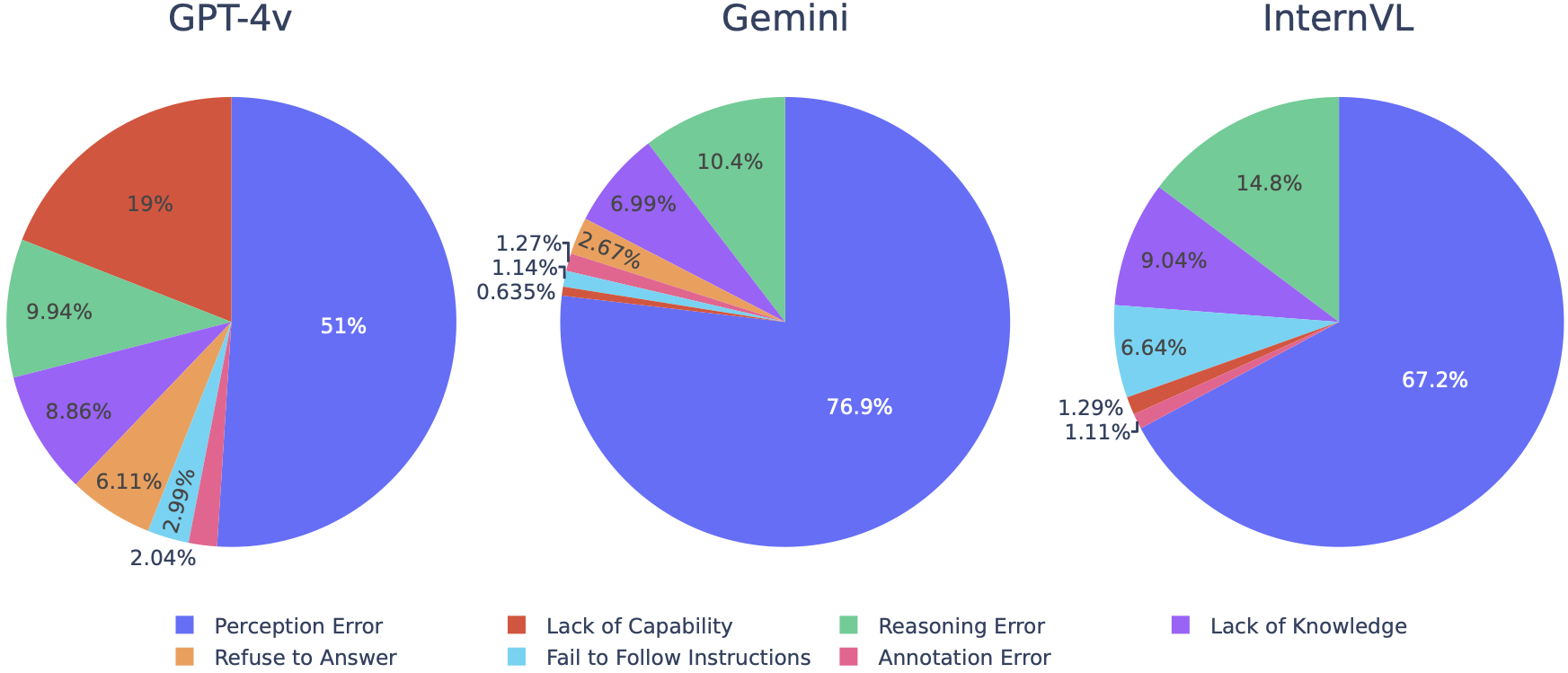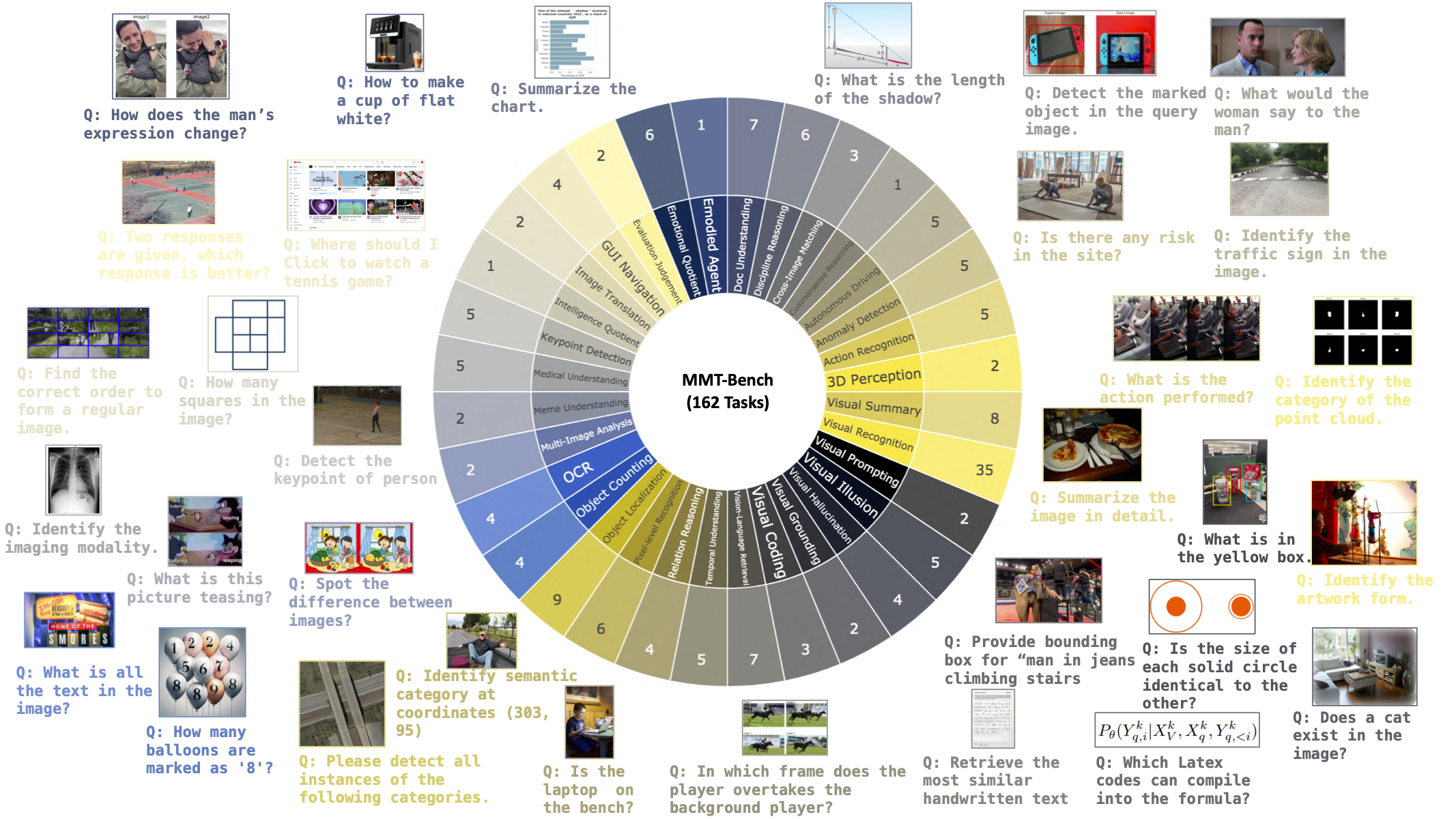

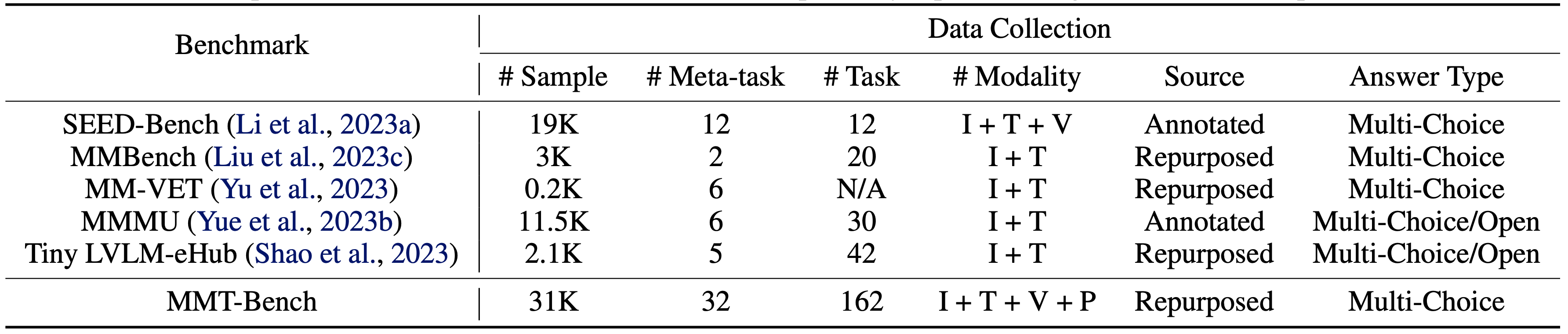
Quantitative results for 30 LVLMs across 32 meta-tasks are summarized, with R representing the average rank. Accuracy is the metric, and the Overall score is computed across all subtasks, excluding visual recognition (VR) as denoted by *. The maximum value of each meta-task is bolded. Meta-tasks are abbreviated for brevity, with full terms in the paper for reference.
Baseline
Open-Source
Proprietary
| Model | Overall | R | VR | Loc | OCR | Count | HLN | IR | 3D | VC | VG | DU | AR | PLP | I2IT | RR | IQT | Emo |
| Overall* | R* | VI | MemU | VPU | AND | KD | VCR | IEJ | MIA | CIM | TU | VP | MedU | AUD | DKR | EA | GN | |
| Frequency Guess | 31.7 | 26.1 | 30.0 | 28.2 | 30.4 | 28.2 | 43.4 | 29.9 | 26.5 | 28.2 | 29.1 | 37.6 | 30.0 | 29.4 | 30.8 | 33.5 | 18.0 | 30.1 |
| 32.2 | 25.9 | 52.1 | 32.8 | 29.3 | 44.4 | 33.7 | 27.0 | 30.0 | 46.5 | 28.5 | 29.1 | 29.5 | 30.9 | 29.7 | 29.4 | 28.0 | 29.0 | |
| Random Guess | 28.5 | 30.0 | 27.1 | 28.1 | 27.2 | 25.0 | 41.6 | 24.3 | 25.5 | 25.0 | 24.8 | 30.3 | 25.4 | 26.6 | 21.2 | 33.4 | 10.5 | 25.4 |
| 28.9 | 29.9 | 50.8 | 25.5 | 31.4 | 36.5 | 32.2 | 28.0 | 25.0 | 48.5 | 26.8 | 27.0 | 28.8 | 27.8 | 26.8 | 25.4 | 27.5 | 24.4 | |
| InternVL-Chat-v1.2-34B | 63.4 | 5.7 | 81.3 | 59.4 | 60.5 | 66.4 | 82.4 | 56.3 | 45.5 | 82.3 | 49.4 | 68.3 | 52.6 | 37.4 | 32.8 | 55.0 | 84.0 | 48.7 |
| 58.2 | 5.7 | 61.5 | 62.5 | 58.2 | 57.0 | 62.2 | 76.0 | 31.0 | 82.8 | 56.8 | 45.2 | 41.8 | 71.8 | 57.8 | 49.4 | 74.5 | 41.2 | |
| Qwen-VL-Plus | 62.3 | 6.7 | 82.6 | 55.3 | 65.6 | 61.1 | 69.9 | 40.7 | 46.5 | 86.5 | 43.6 | 77.3 | 53.4 | 43.1 | 37.8 | 53.0 | 84.5 | 41.6 |
| 56.6 | 6.8 | 50.3 | 61.0 | 67.5 | 58.8 | 55.3 | 76.5 | 31.8 | 81.5 | 61.3 | 45.5 | 33.7 | 73.3 | 59.5 | 46.8 | 85.0 | 32.6 | |
| GPT-4V | 62.0 | 8.3 | 85.3 | 55.6 | 68.0 | 51.6 | 69.6 | 44.9 | 42.0 | 80.3 | 25.0 | 69.8 | 47.7 | 48.2 | 31.8 | 52.5 | 80.0 | 45.1 |
| 55.5 | 8.6 | 47.9 | 61.0 | 60.2 | 51.4 | 53.6 | 73.0 | 43.4 | 70.2 | 55.2 | 44.6 | 53.3 | 74.0 | 55.6 | 53.4 | 80.9 | 39.7 | |
| GeminiProVision | 61.6 | 8.3 | 84.7 | 43.6 | 59.5 | 56.4 | 65.9 | 68.4 | 45.2 | 80.1 | 33.0 | 71.6 | 57.4 | 40.3 | 31.5 | 58.5 | 11.0 | 55.2 |
| 55.1 | 8.5 | 47.5 | 75.8 | 50.9 | 47.4 | 49.5 | 86.5 | 35.0 | 70.2 | 33.3 | 40.5 | 46.0 | 82.6 | 59.5 | 49.2 | 74.5 | 33.4 | |
| LLaVA-NEXT-34B | 60.8 | 7.5 | 76.7 | 61.0 | 64.1 | 66.3 | 70.1 | 38.8 | 48.5 | 85.9 | 56.2 | 69.1 | 50.6 | 41.9 | 22.8 | 54.9 | 76.5 | 50.3 |
| 56.3 | 7.5 | 57.8 | 55.5 | 57.2 | 61.2 | 62.7 | 75.0 | 22.2 | 77.8 | 43.0 | 45.4 | 40.2 | 61.9 | 55.1 | 48.1 | 80.0 | 41.4 | |
| XComposer2 | 55.7 | 11.7 | 75.3 | 47.9 | 43.9 | 51.0 | 69.5 | 32.4 | 40.5 | 73.7 | 42.6 | 62.0 | 46.3 | 43.9 | 31.5 | 50.5 | 8.0 | 53.6 |
| 50.0 | 11.7 | 52.6 | 71.2 | 56.1 | 56.2 | 41.5 | 83.0 | 43.8 | 80.8 | 61.2 | 36.6 | 36.3 | 53.5 | 48.8 | 43.8 | 50.5 | 29.4 | |
| BLIP2 | 54.8 | 12.8 | 75.1 | 54.1 | 48.1 | 29.8 | 66.1 | 27.4 | 47.8 | 78.7 | 33.5 | 43.0 | 51.1 | 46.1 | 28.2 | 53.0 | 14.0 | 43.1 |
| 49.1 | 12.8 | 55.6 | 76.2 | 39.8 | 43.7 | 60.2 | 77.0 | 29.8 | 62.8 | 73.0 | 42.7 | 43.2 | 60.1 | 44.6 | 37.0 | 80.5 | 33.4 | |
| Yi-VL-34B | 54.2 | 14.3 | 74.6 | 47.0 | 58.0 | 59.4 | 65.8 | 28.8 | 38.8 | 74.0 | 41.5 | 56.4 | 40.4 | 38.4 | 19.5 | 51.7 | 68.5 | 39.7 |
| 48.6 | 14.3 | 51.3 | 56.2 | 61.2 | 52.4 | 49.5 | 71.5 | 25.5 | 66.0 | 48.0 | 39.2 | 32.0 | 59.6 | 48.2 | 44.3 | 57.0 | 32.4 | |
| Monkey-Chat | 53.4 | 15.5 | 79.0 | 40.1 | 51.0 | 43.6 | 63.1 | 26.8 | 46.5 | 68.9 | 27.5 | 51.1 | 49.3 | 32.2 | 29.5 | 61.8 | 11.0 | 45.1 |
| 46.0 | 15.8 | 55.3 | 69.5 | 43.6 | 44.6 | 36.3 | 85.5 | 26.0 | 58.8 | 61.7 | 36.8 | 33.3 | 68.0 | 43.6 | 38.1 | 46.0 | 29.8 | |
| DeepSeek-VL-7B | 53.2 | 15.0 | 75.6 | 42.0 | 61.1 | 44.5 | 60.6 | 30.5 | 47.2 | 69.1 | 38.4 | 51.9 | 44.8 | 38.3 | 23.5 | 48.8 | 37.0 | 43.8 |
| 46.5 | 15.2 | 47.7 | 59.8 | 53.5 | 45.4 | 41.0 | 41.0 | 38.8 | 35.0 | 67.2 | 33.1 | 30.7 | 69.7 | 48.8 | 36.4 | 67.5 | 36.8 | |
| Yi-VL-6B | 53.2 | 14.7 | 73.5 | 49.4 | 53.1 | 56.2 | 63.9 | 26.0 | 43.5 | 63.4 | 42.1 | 55.2 | 43.8 | 35.3 | 26.8 | 48.8 | 47.0 | 46.1 |
| 47.5 | 14.5 | 55.8 | 54.5 | 49.2 | 53.0 | 51.8 | 65.5 | 34.2 | 52.0 | 43.3 | 37.6 | 37.0 | 60.6 | 46.9 | 40.2 | 48.0 | 34.8 | |
| LLaVA-NEXT-13B | 53.0 | 15.0 | 74.0 | 35.6 | 51.8 | 59.2 | 63.6 | 32.7 | 50.0 | 75.0 | 44.6 | 53.6 | 46.5 | 34.0 | 26.2 | 50.0 | 50.0 | 44.5 |
| 46.8 | 14.9 | 57.5 | 55.0 | 32.2 | 49.6 | 38.9 | 47.0 | 18.0 | 36.5 | 59.8 | 38.9 | 22.5 | 55.8 | 55.7 | 38.5 | 70.0 | 41.0 | |
| TransCore-M | 52.7 | 13.1 | 73.6 | 40.5 | 50.4 | 54.5 | 71.9 | 27.5 | 45.0 | 75.6 | 35.1 | 45.3 | 46.9 | 38.3 | 25.0 | 53.2 | 15.0 | 46.3 |
| 46.9 | 12.9 | 55.6 | 76.8 | 51.9 | 43.7 | 38.6 | 85.5 | 34.2 | 52.8 | 65.8 | 29.7 | 28.8 | 61.1 | 46.5 | 38.4 | 39.5 | 35.6 | |
| QWen-VL-Chat | 52.5 | 16.0 | 77.5 | 33.7 | 46.9 | 46.7 | 63.9 | 27.5 | 45.0 | 73.0 | 26.5 | 51.5 | 50.9 | 32.7 | 30.5 | 57.4 | 13.5 | 45.4 |
| 45.4 | 16.3 | 50.9 | 74.2 | 42.4 | 40.2 | 35.9 | 86.0 | 30.0 | 49.2 | 58.3 | 37.3 | 30.8 | 67.1 | 45.4 | 35.6 | 55.0 | 30.2 | |
| Claude3V-Haiku | 52.2 | 17.7 | 74.3 | 44.8 | 54.4 | 51.1 | 63.6 | 34.6 | 38.2 | 67.6 | 26.9 | 69.8 | 46.2 | 35.5 | 22.8 | 50.0 | 59.5 | 35.2 |
| 46.4 | 17.7 | 42.9 | 53.8 | 43.2 | 41.2 | 53.3 | 70.5 | 31.5 | 34.8 | 52.5 | 35.9 | 34.2 | 62.7 | 34.1 | 40.4 | 54.5 | 35.1 | |
| XComposer | 52.1 | 17.1 | 75.4 | 40.4 | 44.1 | 39.9 | 66.5 | 49.7 | 47.0 | 72.1 | 27.2 | 36.6 | 47.9 | 39.6 | 24.5 | 50.2 | 14.0 | 45.9 |
| 45.6 | 17.3 | 53.4 | 63.8 | 40.6 | 43.4 | 42.3 | 78.0 | 29.0 | 66.2 | 52.3 | 33.1 | 28.3 | 55.6 | 40.8 | 39.3 | 38.5 | 34.2 | |
| mPLUG-Owl2 | 52.0 | 17.3 | 76.5 | 45.8 | 44.5 | 47.6 | 63.4 | 27.6 | 45.2 | 66.6 | 33.0 | 42.4 | 45.2 | 41.6 | 25.5 | 52.0 | 18.0 | 42.0 |
| 45.0 | 17.5 | 58.5 | 59.0 | 40.1 | 49.4 | 32.9 | 85.5 | 30.0 | 55.0 | 57.7 | 31.9 | 27.3 | 63.4 | 45.5 | 38.1 | 35.0 | 27.8 | |
| RBDash-v1-13B | 51.8 | 15.7 | 72.2 | 42.2 | 53.6 | 51.6 | 66.6 | 26.3 | 40.8 | 75.5 | 36.9 | 48.1 | 47.1 | 38.3 | 22.5 | 55.9 | 14.0 | 43.4 |
| 46.1 | 15.3 | 57.1 | 67.5 | 51.4 | 45.7 | 33.2 | 78.0 | 39.0 | 32.0 | 64.2 | 31.6 | 25.5 | 59.3 | 46.3 | 38.1 | 53.5 | 32.4 | |
| LLaVA-v1.5-13B | 51.7 | 15.3 | 73.8 | 38.8 | 51.8 | 55.1 | 65.8 | 27.2 | 39.8 | 70.4 | 37.4 | 45.7 | 46.6 | 37.6 | 28.0 | 58.2 | 13.5 | 45.3 |
| 45.7 | 15.2 | 58.1 | 66.0 | 43.9 | 48.3 | 31.4 | 79.0 | 35.8 | 28.5 | 62.5 | 33.3 | 27.5 | 58.6 | 46.6 | 39.4 | 40.5 | 37.5 | |
| CogVLM-Chat | 51.6 | 17.5 | 77.7 | 24.7 | 48.5 | 49.8 | 66.0 | 26.1 | 42.2 | 69.8 | 28.8 | 49.1 | 46.3 | 33.2 | 23.8 | 61.6 | 14.0 | 50.3 |
| 44.2 | 17.9 | 52.4 | 75.5 | 39.8 | 43.4 | 28.2 | 82.0 | 28.0 | 70.8 | 45.8 | 35.5 | 28.3 | 65.9 | 44.9 | 36.9 | 48.0 | 29.9 | |
| ShareGPT4V-7B | 51.5 | 16.4 | 74.2 | 36.0 | 47.8 | 50.9 | 62.4 | 27.8 | 45.2 | 71.6 | 35.4 | 47.9 | 46.2 | 39.2 | 21.8 | 59.8 | 14.0 | 44.3 |
| 45.1 | 16.4 | 54.5 | 70.5 | 47.1 | 48.2 | 26.3 | 83.0 | 27.8 | 38.0 | 64.3 | 32.1 | 30.0 | 60.8 | 46.1 | 38.9 | 42.0 | 28.9 | |
| LLaVA-NEXT-7B | 51.1 | 18.1 | 73.3 | 29.5 | 52.0 | 56.8 | 59.9 | 28.7 | 43.2 | 69.8 | 37.0 | 49.7 | 47.9 | 32.6 | 22.8 | 49.0 | 47.5 | 48.1 |
| 44.6 | 18.0 | 57.8 | 54.0 | 38.5 | 44.3 | 34.6 | 42.5 | 18.8 | 32.5 | 67.8 | 39.1 | 23.3 | 55.5 | 53.5 | 37.0 | 65.0 | 31.6 | |
| LLaVA-v1.5-13B-XTuner | 51.1 | 16.8 | 72.5 | 40.7 | 46.8 | 54.1 | 66.5 | 26.4 | 47.5 | 68.8 | 35.6 | 47.0 | 44.2 | 38.3 | 26.0 | 52.4 | 14.0 | 51.0 |
| 45.1 | 16.5 | 54.4 | 66.5 | 47.9 | 52.0 | 28.8 | 82.0 | 39.2 | 37.0 | 56.8 | 28.3 | 28.3 | 49.1 | 44.4 | 37.3 | 33.5 | 40.9 | |
| LLaVA-InternLM2-7B | 50.8 | 17.5 | 73.3 | 38.9 | 49.5 | 51.8 | 67.8 | 27.7 | 49.5 | 66.4 | 36.9 | 37.7 | 43.7 | 35.1 | 14.2 | 58.0 | 0.0 | 51.1 |
| 44.4 | 17.4 | 52.3 | 62.5 | 45.1 | 57.2 | 35.2 | 83.0 | 34.2 | 55.8 | 58.2 | 26.8 | 18.5 | 57.8 | 45.1 | 33.7 | 35.5 | 35.2 | |
| LLaVA-v1.5-7B-XTuner | 50.2 | 19.5 | 72.5 | 41.1 | 46.0 | 49.9 | 62.1 | 26.0 | 45.5 | 66.4 | 35.3 | 42.8 | 45.8 | 42.5 | 25.5 | 53.9 | 11.5 | 44.2 |
| 43.9 | 19.3 | 60.1 | 56.5 | 42.6 | 47.2 | 28.4 | 80.5 | 32.2 | 41.2 | 63.2 | 29.9 | 24.2 | 52.5 | 43.4 | 37.2 | 32.0 | 30.5 | |
| SharedCaptioner | 49.9 | 19.6 | 72.8 | 41.8 | 47.8 | 46.2 | 63.1 | 27.0 | 44.2 | 61.9 | 27.0 | 39.5 | 46.7 | 33.5 | 25.0 | 59.5 | 14.5 | 39.9 |
| 43.2 | 19.5 | 55.1 | 53.8 | 45.4 | 38.3 | 33.6 | 82.5 | 20.2 | 57.8 | 56.8 | 32.6 | 28.7 | 59.4 | 44.7 | 38.4 | 45.0 | 29.6 | |
| LLaVA-InternLM-7B | 49.7 | 19.6 | 70.1 | 38.7 | 47.6 | 46.0 | 62.0 | 25.5 | 42.0 | 65.0 | 26.5 | 43.9 | 45.6 | 38.3 | 25.0 | 52.4 | 14.0 | 47.0 |
| 43.9 | 19.3 | 57.5 | 58.2 | 45.6 | 46.5 | 33.2 | 75.5 | 33.0 | 57.0 | 59.7 | 28.0 | 27.3 | 52.0 | 42.2 | 38.1 | 46.5 | 37.6 | |
| LLaVA-v1.5-7B | 49.5 | 20.3 | 72.8 | 34.3 | 45.0 | 47.5 | 61.6 | 26.1 | 44.8 | 68.1 | 34.0 | 40.8 | 46.6 | 36.0 | 22.2 | 58.0 | 12.5 | 42.5 |
| 43.1 | 20.3 | 57.6 | 70.5 | 33.3 | 49.1 | 31.6 | 81.0 | 27.8 | 37.5 | 62.3 | 31.7 | 27.5 | 56.8 | 45.1 | 35.6 | 42.5 | 20.4 | |
| LLaMA-Adapter-v2-7B | 40.4 | 27.5 | 62.3 | 32.5 | 35.0 | 30.1 | 46.5 | 24.1 | 33.8 | 34.8 | 25.2 | 30.2 | 43.9 | 33.1 | 18.2 | 44.9 | 11.0 | 36.0 |
| 34.1 | 27.4 | 36.4 | 40.5 | 33.8 | 30.4 | 34.9 | 71.0 | 33.2 | 42.2 | 35.8 | 31.1 | 25.8 | 52.0 | 29.1 | 32.0 | 25.0 | 29.9 | |
| VisualGLM-6B | 38.6 | 27.1 | 55.0 | 33.1 | 33.8 | 31.1 | 39.2 | 26.0 | 36.8 | 40.5 | 31.1 | 39.1 | 39.2 | 32.4 | 26.8 | 43.8 | 14.0 | 33.1 |
| 33.9 | 27.0 | 28.9 | 44.8 | 27.1 | 34.5 | 35.2 | 65.0 | 28.0 | 35.8 | 48.2 | 30.8 | 23.5 | 44.0 | 26.2 | 29.6 | 37.5 | 21.1 |